- Prelude
- Material Editor
- Optimizing Shaders
Prelude
I saw some recent advice shared around about optimizing shaders, which was well-intended, but not correct. I want to clear up some myths around optimising shaders in this article – specifically around the material editor inside Unreal Engine.
*Though this information technically applies to Niagara in some aspects as well as because Niagara produces compute shaders.
About this Article
I’m no expert and this information I’ve picked up over the years, which I’ve purposely simplified to be more accessible including the use of semantic terminology – some information is missing and it’s a complex topic. I openly invite everyone to add to the discussion in a friendly manner.
Material Editor
First we must understand what the Material Editor actually is.. which quite simply is a tool which is generating multiple shaders with the help of a node graph and some metadata (blend modes etc), all stored in a neat little asset – a material.
Each atomic (green) node in the graph instructs the compiler what code (HLSL in this case) to generate, and at the end we will have several HLSL shaders (depending on usage flags and domain types, but usually we will have several vertex shaders and pixel shaders for one material.

Generated Shader Code
The intermediate HLSL code which is generated can be viewed from Window > Shader Code > HLSL Code. From here we can also see the platform-specific code which is generated – this can be HLSL or even transpiled to GLSL (Android, for example).

You will notice a lot of templated code (this comes from MaterialTemplate.usf) – don’t be alarmed as the compiler will remove anything we don’t need at the end.
Material Instances
Material Instances are a concept which combines the traditional concept of materials (i.e. a package which contains all the parameters for a given set of shaders, just like Unity’s definition), and class inheritance. It’s an interesting concept and all this basically means is we can have a parent-child hiearchy of material instances which can inherit from each-other.
These waters get muddied however once we consider that the shaders which material instances use can be overriden using material property overrides (i.e. blend mode, two-sided overrides etc), material layers, and static parameters.
We won’t even touch on Landscape materials as this is a whole other rabbit hole..
Optimizing Shaders
Instruction Counts
Instruction counts basically tell us two things..
- Size in memory (and on disk) of the shader(s) – more instructions, more memory our shaders will consume
- Potentially a very high level view of how slow our shader is.. except also not quite (keep reading)
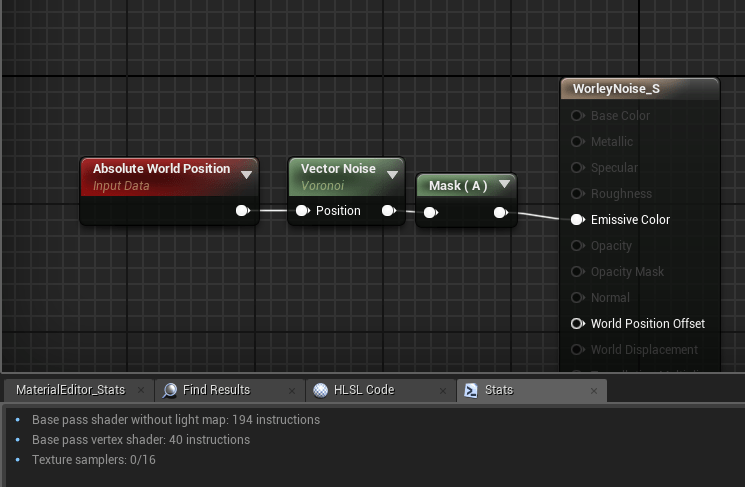
Unreal provides you with some stats around how many instructions your material generates with its Stats tab – this information is a useful first look at what your material is generating.
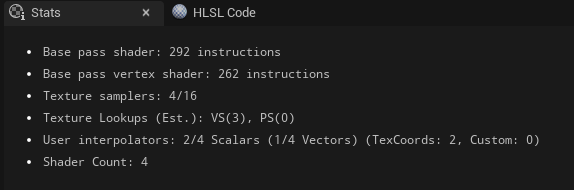
The problem arrives from something we just brought up earlier.. this is as estimate based on the intermediate HLSL code that is generated! So this is often inaccurate and only gives us a very high level view. To fix this problem we can use the Platform Stats tool inside the Material Editor to view the real instruction counts (and other stats) for the shaders generated for those platforms. This works because it will use the compilers linked for those platforms.
This view is incredibly useful as it will also tell us a bit more about the shaders generated for different usage flags, i.e. your vertex shader for a skeletal mesh is going to be a lot heavier than a static mesh!

Static Parameters
Before we talk about that, let’s talk static parameters! These are what they are referred to inside the engine code, but essentially we’re referring to..
- Base property overrides (blend mode, shading model, two-sided etc.)
- Material layers
- Static switches and static channel mask parameters (but not regular channel parameters – those are just dot products)
- Landscape layers – each landscape proxy will produce new permutations based on which layers are painted and in which order (as far as I know these are not shared across proxies, unless this has changed in recent versions)
These are properties which can be changed inside material instances and will dirty the permutation, causing new shaders to be generated for this material.
This obviously will produce entire copies of our shaders to accomodate for those properties/resources introduced at compile-time, causing more shader memory to be consumed by more instructions.
In older versions just using the static parameter overrides would cause this to be dirtied, but this seems to be resolved in recent versions.
Usage Flags
Usage flag further this problem (all the checkboxes in your material which determines what primitive types the material can be rendered with). This is because each static parameter will produce new shaders for each usage flag (though some shaders are thankfully shared).
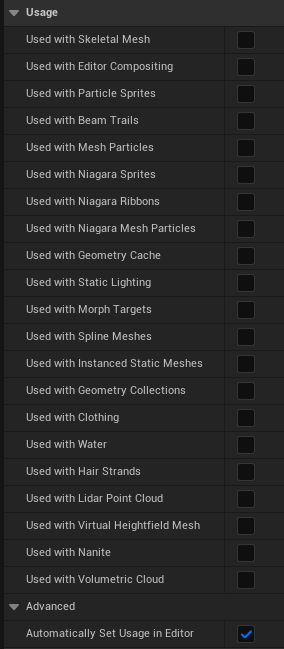
Avoiding this issue is actually quite simple – disable Automatically Set Usage in Editor; this disables the functionality of automatically ticking flags in materials as the material is applied to those primitive types at editor-time, leaving it up to the author to explicitly define what the material is used with.
GPU Cycles
It’s probably common knowledge that the number of instructions plays a part in the performance of our materials, right? The more instructions you need to execute, the slower the shader is to execute.. right? Well actually not quite..
Not every instruction produces is 1:1 in the assembly it generates, nor is every instruction executed at the same speed (the number of cycles on the GPU).
Unfortunately this is not something Unreal shows you, and can be a bit compiler-dependent. But with some experimentation, knowledge of HLSL, some math knowledge, and some understanding of what is going on, you can figure out the general output of instructions & their cycles.
I highly recommend shader-playground.timjones.io for viewing the assembly and GPU cycles of your instructions. I use the Radeon GPU Analyzer for my work.

Examples
Based on the Radeon compiler, here’s what I’ve found for some common instructions..
| Instruction | Assembly | Cycles | Notes |
| * (operator) | mul | 4 | |
| + (operator) | add | 4 | |
| – (operator) | – | – | Seems to be free to flip a value to negative |
| / (operator) | mul, rcp | 20 | Compiled to multiply by reciprocal (16 cycles) |
| pow | exp | 16 | If constants are used this will vary into a string of muls |
| sqrt | sqrt | 16 | |
| sin | sin | 16 | |
| cos | cos | 16 | |
| tan | sin, mul, rcp, cos | 52 | Compiled to use identity of tan = sin/cos, where the divide is a mul rcp like a regular divide, making this one of the most expensive instructions! |
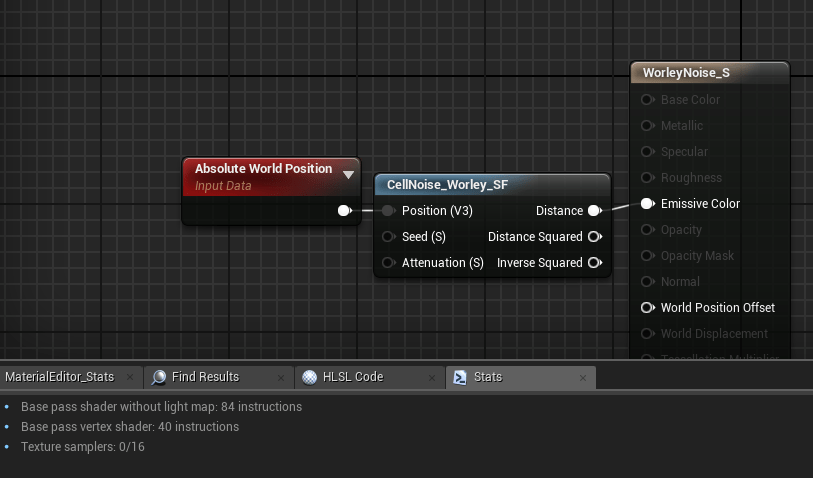
Distance Squared
Knowing this we can determine that finding the distance between two points on the can be a fairly expensive operation – because the distance is just the length of the delta vector!
AB == B – A, so distance(A, B) == length(AB)!
Getting the length of a vector is determined by sqrt(x^2 + y^2 + z^2) (scaling to whatever dimension you’re using, we’re assuming float3).
Fun Fact
Those familiar with pythagorean theorem will see something very fimiliar here, because this is in-fact, the exact same as c = sqrt(a^2 + b^2), where a and b are the lengths of the two orthonormal edges, which we can also visualize as our point or vector on the triangle.
With this knowledge we can see just getting the distance/length costs us ~28 cycles!
| length(A) | sqrt(x^2 + y^2 + z^2) | sqrt, mul, mac, mac | 28 cycles |
I bring this up because we can optimize this by using distance squared where possible instead – i.e. for comparing distance values we can just use distance squared! (just square your comparison value if it’s a regular distance value)
If we’re building a (signed) distance field or doing this in a loop then we can do this using distance squared too, and then sqrt the result, so we only need to sqrt once!
How do I get Distance Squared? Answer: Dot Product
Obtaining the distance squared can be done with the dot product, i.e. dot(x, x) – this is just a very easy way of returning the distance squared.
You may also see this used a lot in C++ code to optimize opterations, so it’s not exclusive to the GPU!
Constant Optimization
In short, the compiler will evaluate constants and operations involving constants (where it can) at compile time, which provides us with some very useful optimizations..
Here’s some example expressions and what they’ll be simplified to by the compiler..
| Expression | Compiled To |
| (x + 0) * 1 | x |
| sin(0) | 0 (radians) |
Generally I recommend not trying to beat the compiler and re-valuating expressions yourself (I used to try and do this), i.e. replacing divides with multiply rcp – because you should just let the compiler decide and do the hard work! 😉
It also keeps your code/node graph readable and easier to understand.
Custom Node
I’ve seen a note about how this doesn’t work inside custom nodes, but this is actually untrue because the optimzation occurs when the assembly is produced and thus won’t necessarily be reflected by the stats tab in Unreal.
Example – Pow
An example which sparked me to write this article is the use of the pow instruction.
When using a constant exponent the compiler will optimize this into a string of multiply instructions if this is less cycles than the exp instruction which it would otherwise generate!
What this means is you can use the pow node with a constant exponent and this will determine how expensive it is (maxing at 16 cycles for an exp instruction).
For example these two expressions are equal because the exponent of 2 is constant.
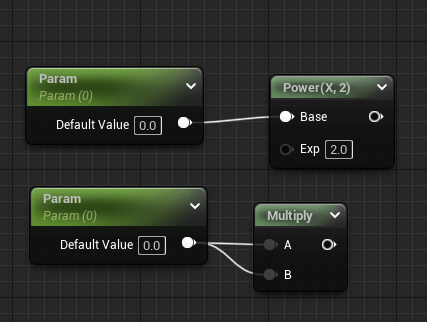
| Expression | Compiled to | Cycles | Notes |
| pow(x, 2) | mul | 4 | |
| pow(x, 5) | mul, mul, mul | 12 | |
| pow(x, 16) | exp | 16 | Seems to hit the limit where exp is used |
| pow(x, 0.5) | sqrt | 16 | Reciprocal values (1/x) as exponents will produce the root |
Optimized broken by Varyings
This won’t work if the expression cannot be evaluated at compile time (this may require some math knowledge) – so varyings (parameters, texture samples, resources etc) will not be able to be evaluated and thus be as optimized. i.e. a varying used as a pow exponent won’t be optimized, but as the base arg it will be because x^3 can be evaluated to x*x*x.
Taking Advantage of This
With an understading of math and the compiler, we can take advantage of this optimization in our workflow – especially if we are using a material function-heavy workflow (which I recommend).
For example we can write a generic UV manipulation function, which by default has some input values which we know will get optimized out. You want to add functionality? Just input a parameter! No need for passing switches around!

We can apply this everywhere! As long as these inputs are not varying and use values which we know the math operations will cancel out, we can do this! Just make sure you do check the generated code.
Sampling Textures – Optimising for Pre-Fetches (Vertex Interpolators) (Older Hardware)
Important Note from the Author
I written this section originally with the prelude that this would be a divisive topic as the impact would vary on different hardware. Epic’s own docs mention this is specific to mobile optimization – this is because the impact is greater on ES2.0 from my reading on this topic.
Since then I have rewritten this section to provide more accurate reasoning with my updated understanding of the topic, but it none-the-less still a complex topic where the impact could still be variable.
On older hardware the GPU will perform and optimization to sampling textures (ES2.0) which is to pre-fetch them before the pixel (fragment) shader begins – this is called a pre-fetch.
*This is stated to generally have next to no performance penalty on modern hardware
This optimization is broken when the texture fetch becomes a dependent texture fetch, where the sampling of the texture relies on some math to be executed before the sample can begin, thus the GPU is unable to perform the pre-fetch.
This can happen under a variety of situations..
- Modifying the UVs used to sample the texture in any form (even a swizzle will cause a dependant texture read)
- Branching the texture sample with some conditionals
- Sampling a texture relying on the result of another texture sample
This is explained by Apple’s own documentation here.
Relying on Another Texture Fetch
Dependent texture fetches are often confused with another situation (which is still very much a dependant texture fetch) which is sampling a texture using the result of another texture sample (i.e. using a noise texture to distort the UVs of another texture).
Make no mistake though, this is still a dependent texture fetch, but it is not the sole definition.
I have heard this specific situation can still incur a performance penalty on more modern hardware, but I don’t have anything concrete about this right now.
Vertex Interpolator & Custom UVs
To avoid dependent texture fetches under the most common circumstance, which is modifying the UV, we can pre-calculate the UV in the vertex shader and pass the new UVs to the pixel shader. Internally this utilises the TEXCOORD register, though on different hardware there are different limits on how many we have available. Unreal refers to these as user interpolators.
To do this we can utilise a feature called Custom UVs, or the more recent Vertex Interpolator (introduced a few years ago to automate the annoyance of managing Custom UVs). Vertex Interpolator is generally preferred as this will pack floats together instead of you having to manually manage a Custom UV.
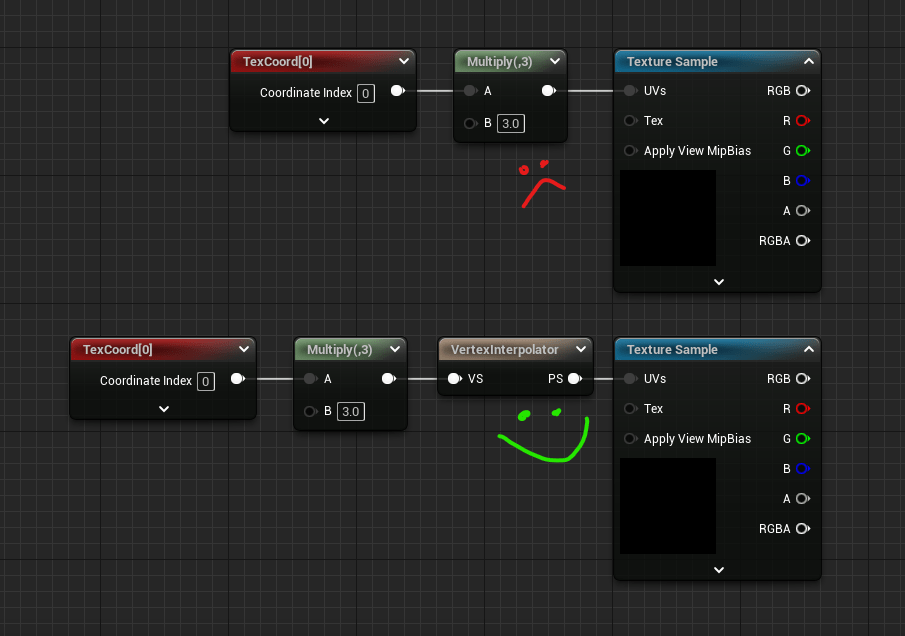
Each time you do this it will add to the User Interpolators stat (though this can be confusing to look at).
You should note that also using custom UV channels such as TexCoord1 will add new interpolators, and you only have a limited number of interpolators depending on the platform (usually 16)!
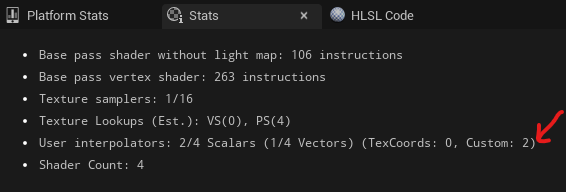
As you may have guessed, this will limit some per-pixel manipulation techniques such as PoM, distortion, parallax mapping etc. which can leave these deceivingly more expensive (scaling on different hardware).
Conclusion
There is a lot of things to consider when optimizing shaders, especially when using the Material Editor inside Unreal..
- As always different hardware will require different optimizations – it shouldn’t need to be said but always check for yourself
- Instruction counts are generally less important than the actual operations being executed (which we can see in the assembly), though it is still a nice high level view of our shader memory usage
- GPU cycles are the true(r) measure of performance – knowledge of math for revaluating expressions and knowledge of the compiler are invaluable here, i.e. divide becomes mul rcp (20 cycles, vs just 4 cycles for a mul). Recommend using https://shader-playground.timjones.io/
- Distance squared is some voodoo magic for optimizing our operations on the CPU and GPU
- Manipulating UVs for texture samples in the pixel shader can stall the GPU, but can be resolved with clever use of vertex interpolators/custom UVs
- Branching can stall the GPU (though we haven’t covered this in detail)
- Usage flags should be limited in order to limit the shaders used because we can’t compile out the ones we don’t need
- Static parameters (switches, material layers, base property overrides, landscape layers) can all cause permutation bloat and thus an increase in instruction counts & thus shader memory
- Constants are optimized at compile-time vs varyings (textures, parameters etc.) so we should generally opt to use these unless there is an actual good reason to expose something as a parameter. Material functions become a lot more powerful workflow-wise once you understand how to manipulate this.
And that’s all for now! I may write more in the future, such as about branching (and its limitations on sampling textures), and using ddx/ddy/fwidth etc.
There’s still much more to the puzzle such as shader occupancy, but hopefully this dispells a lot of confusion and brings to light a lot of niche information which isn’t easily available in one place to non-graphics programmers.